R语言数据结构—数据框
实验目的:
本关会介绍 R 语言中的数据框,也会顺便介绍一些常用的功能函数。然后,就轮到你来亲自上手,简单操作一下这些数据结构,需要使用到的函数都在下面的相关知识里,根据右边的代码注释完成相应任务。
实验环境:
Tempo大数据平台
实验内容:
为了完成本关任务,你需要认真学习以下函数:
data.frame(): 用来建立数据框的函数;
str(): 查看数据框结构。
数据框
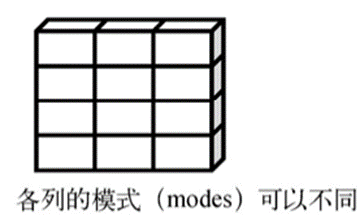
由于不同的列可以包含不同模式(数值型、字符型)的数据,数据框的概念跟矩阵相比更为一般。
数据框将是你在R中最常处理的数据结构。

这是某平台上的实训数据。
这个表里包含了数值型和字符型数据,我们没有办法为它建一个矩阵,所以,这种情况下,数据框是最好的选择。
创建数据框:
数据框可以通过函数 data.frame(col1, col2, col3, ...) 来创建。
其中列向量col1,col2,col3可为任何类型。
每一列数据的模式必须唯一,不过你却可以将多个模式的不同列放到一起组成数据框。
比如执行以下代码后:
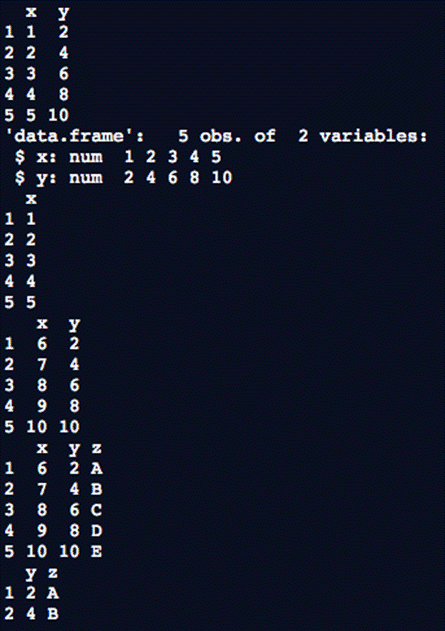
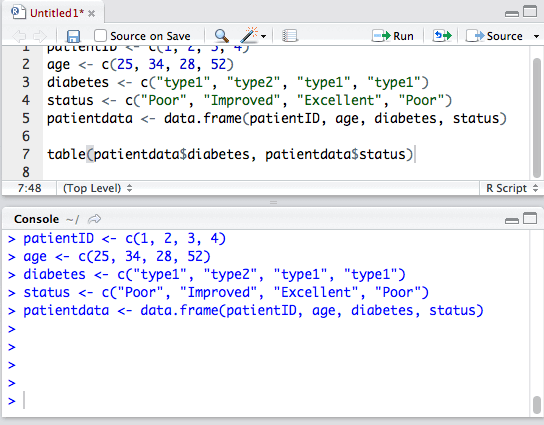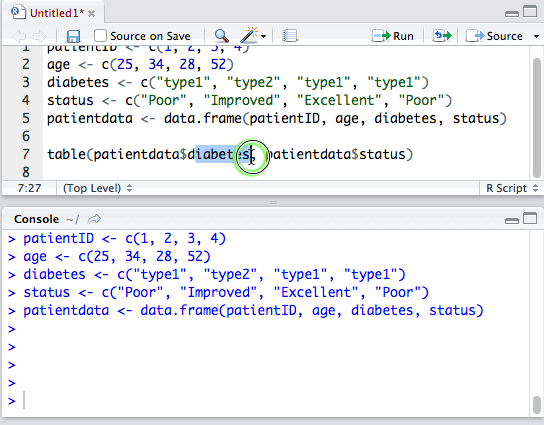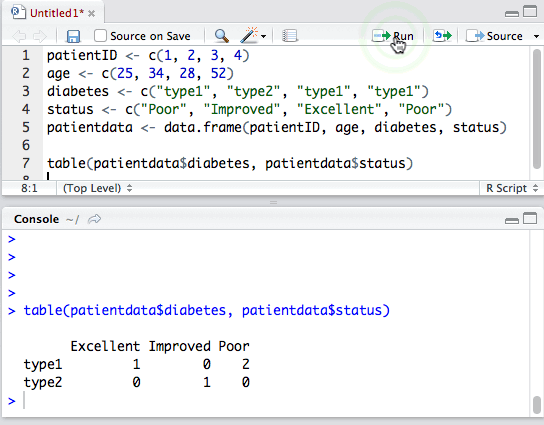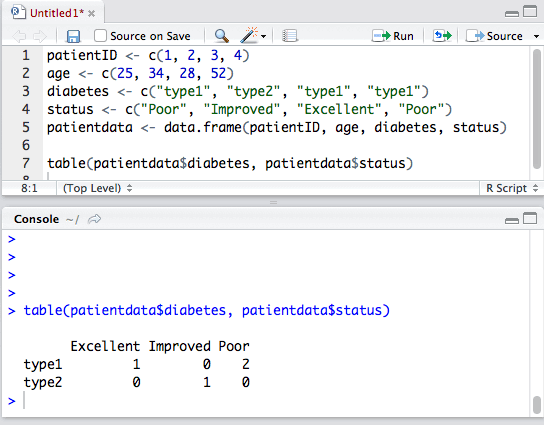
patientID <- c(1, 2, 3, 4)
age <- c(25, 34, 28, 52)
diabetes <- c("type1", "type2", "type1", "type1")
status <- c("Poor", "Improved", "Excellent", "Poor")
patientdata <- data.frame(patientID, age, diabetes, status)
patientdata
1
2
3
4
5
6
1
2
3
4
5
6
1
2
3
4
5
6
1
2
3
4
5
6
我们能得到结果:

如何访问数据框中的数据
我们可以像之前一样使用索引来访问数据框中的元素,也可以用数据框特有的新办法来访问,那就是$符号。
举个例子来看看吧:
patientdata[1:2]
1
1
1
1
得到的结果是:

patientdata[c("diabetes", "status")]
1
1
1
1
得到的结果是:

patientdata$age
1
1
1
1
得到的结果是:
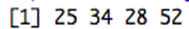
$符号被用来选取一个给定数据框中的某个特定变量。它还有个很好用的用法,就是通过符号$,我们可以用列名做联表。
我们也可以将不存在的列w,添加到数据框patientdata上。
patientdata$w <- c("A", "B", "C", "D")
1
1
1
1
数据框中常用的函数
1.使用函数str()可以查看数据框结构,可以轻松得知各列保存着哪种类型的数据。比如查看如下的数据结构:
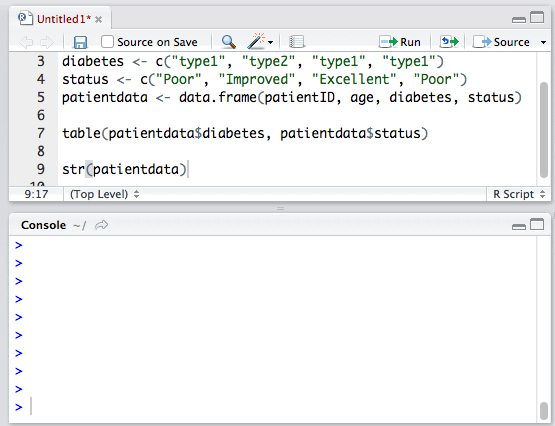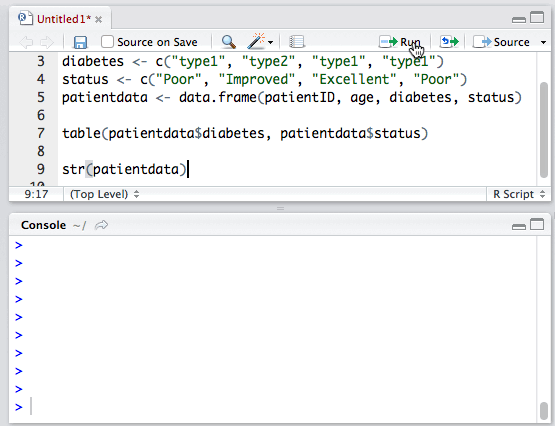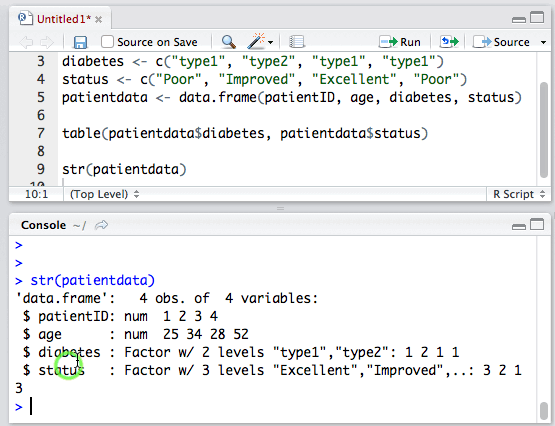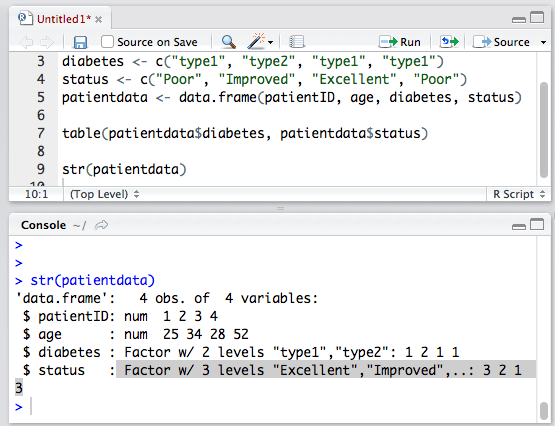
从结果可以看出,diabetes列和status列都是因子(factor)列。因子我们会在下一节中讲到。
2.names()函数用于返回数据框点的列名。使用 %in%运算符与names()函数,能够快速选取特定列。
比如:数据框b拥有a、b、c三个列,使用:
d[ ,names(d)%in%c("b","c")]
1
1
1
1
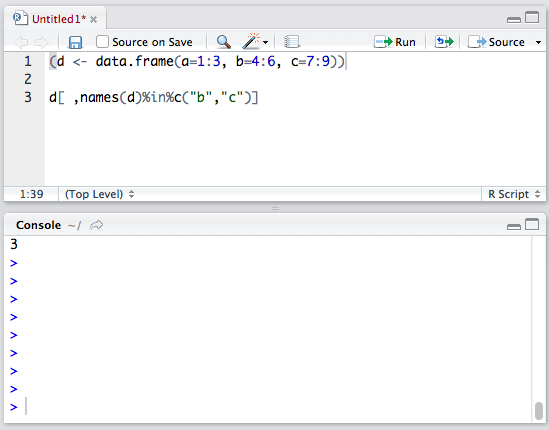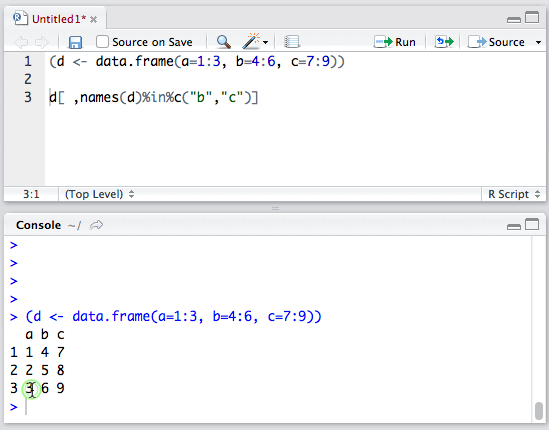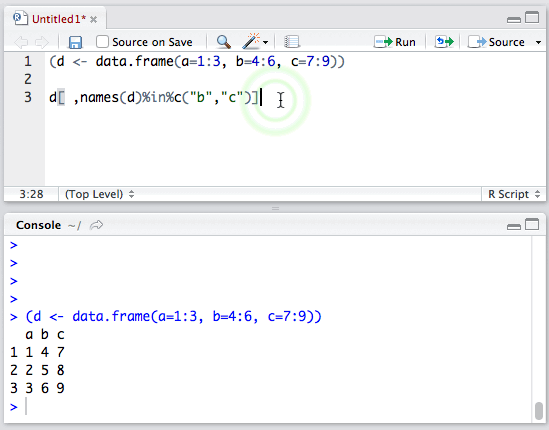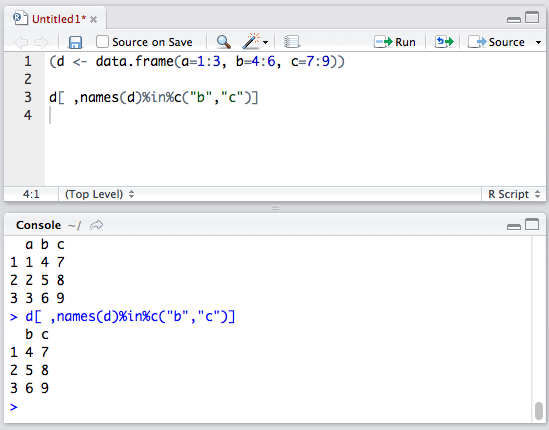
只选取并输出b、c列。
反之,使用!运算符可以排除特定列。
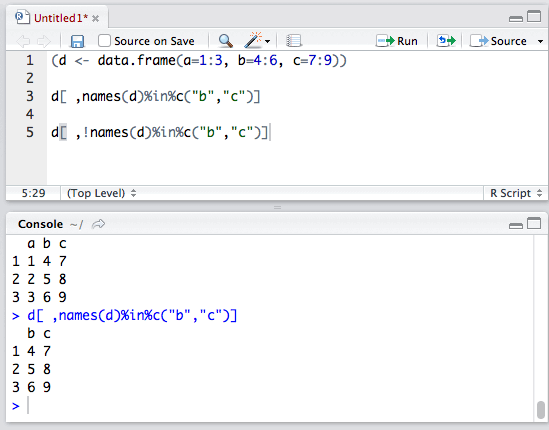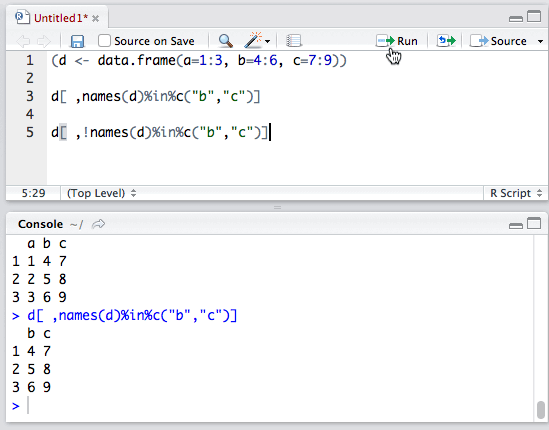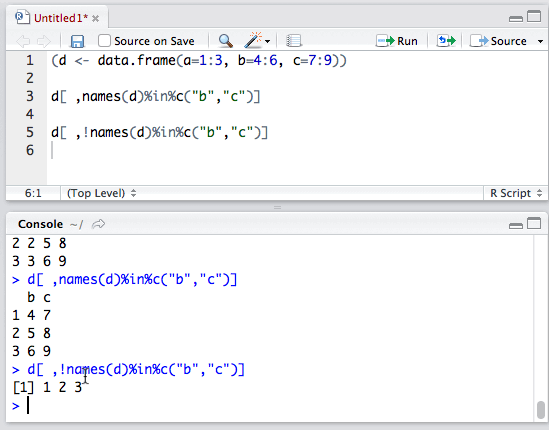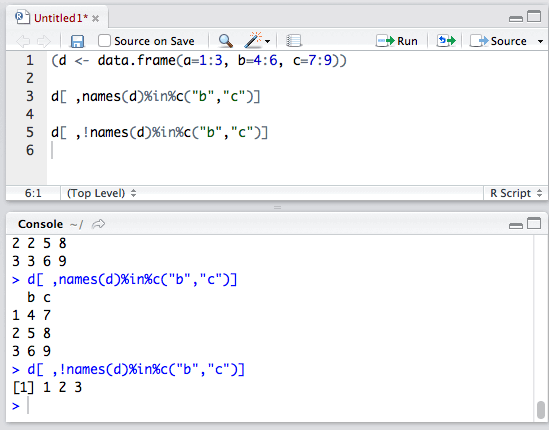
我们就这样得到了列a。细心的同学可能发现了,为什么列a变成了向量呢?
这是因为,列是一维时,返回值与相应列的数据类型不同。想避免这种类型转换的话,只需要设置drop=FALSE即可:
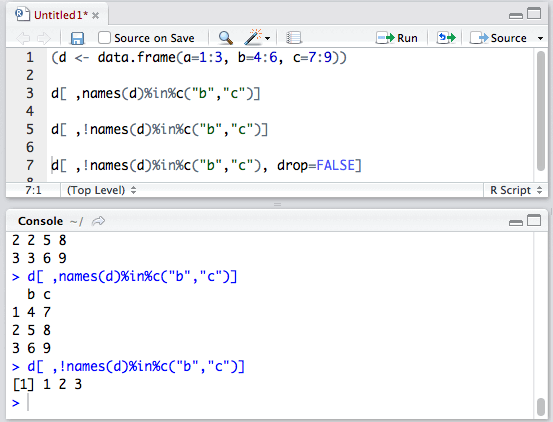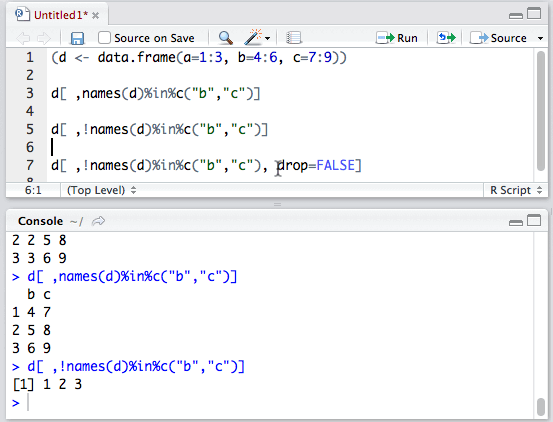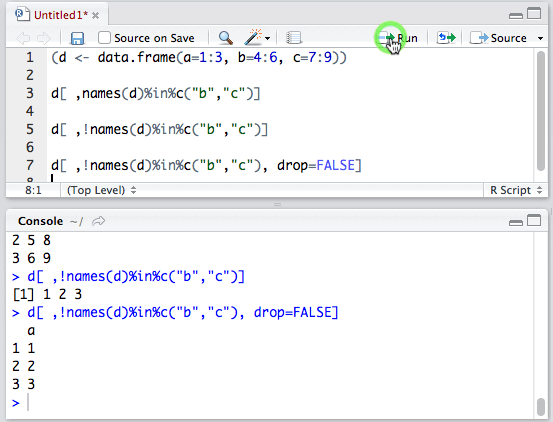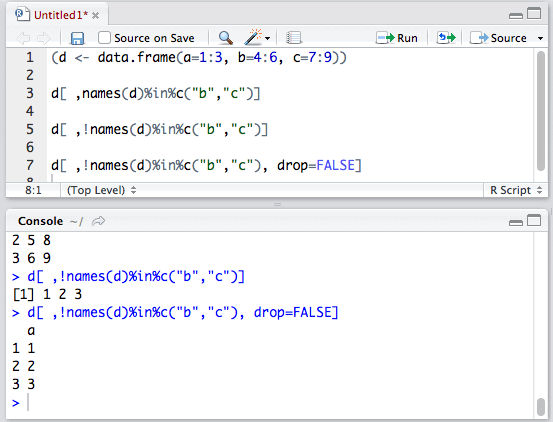
编程要求
请仔细阅读右侧代码,根据方法内的提示,在Begin - End区域内进行代码补充。
测试说明
补充完代码后,点击测评,平台会对你编写的代码进行测试,当你的结果与预期输出一致时,即为通过。
你需要输出的结果为: