R语言的数据结构—向量
实验目的:
本关会介绍R都有哪些对象类型用来存储数据,也会顺便介绍一些常用的功能函数。然后,就轮到你来亲自上手,简单操作一下这些数据结构,需要使用到的函数都在下面的相关知识里,根据右边的代码注释完成相应任务。
实验环境:
Tempo大数据平台
实验内容:
为了完成本关任务,你需要认真学习以下函数:
c(): 用来建立向量的函数;
seq(): 该函数用于创建包含from~end数值的向量;
rep(): 该函数用来创建保存重复值的向量;
length(): 用来计算向量长度的函数;
names(): 该函数用来对向量各元素命名。
R拥有许多用于存储数据的对象类型,包括标量、向量、矩阵、数组、数据框和列表。它们在存储数据的类型、创建方式、结构复杂度,以及用于定位和访问其中个别元素的标记等方面都会有所不同。
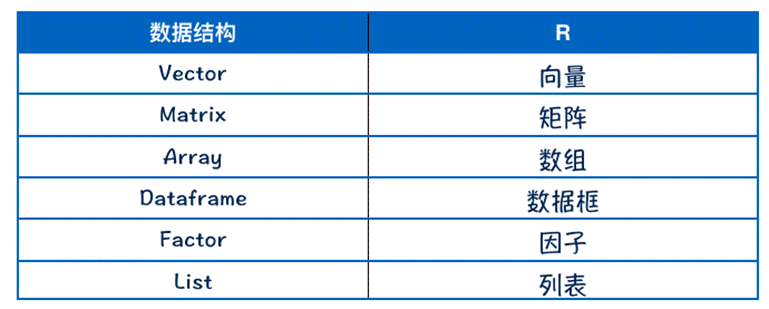
这么多数据结构,都有什么区别呢?看看下图,你也许就会对各种数据结构有一个更直观的印象了。
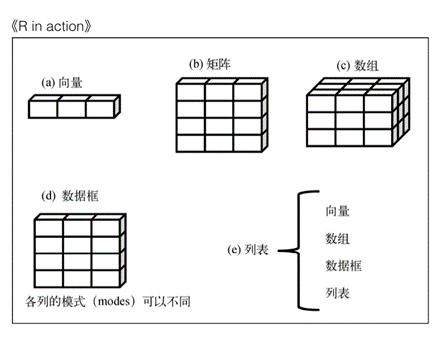
让我们从向量开始,逐个探究每一种数据结构吧。
向量
向量是用于存储数值型、字符型或逻辑型数据的一维数组。我们可以用函数c()来创建向量。比如:
a <- c(1,2,3,4,6,7,9,0)
b <- c("a","b","c")
c <- c(TRUE, TRUE, TRUE,TRUE)
1
2
3
1
2
3
1
2
3
1
2
3
仔细看看,发现了什么?
怎么每一个向量中的数据好像都是相同类型的?没错!记住!
同一向量中无法混杂不同模式的数据!
:运算符是向量常用的运算符,它是给懒人发明的,为什么这么说呢?
通过下面的例子你就会明白。
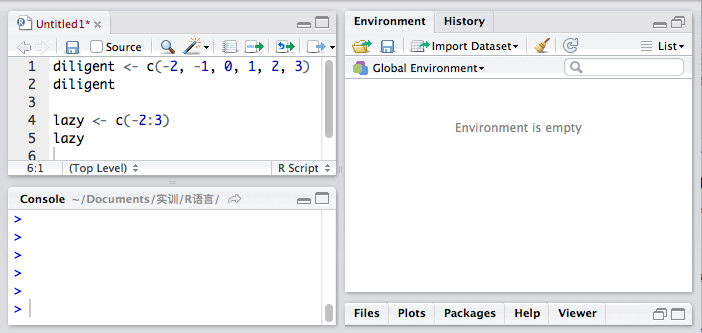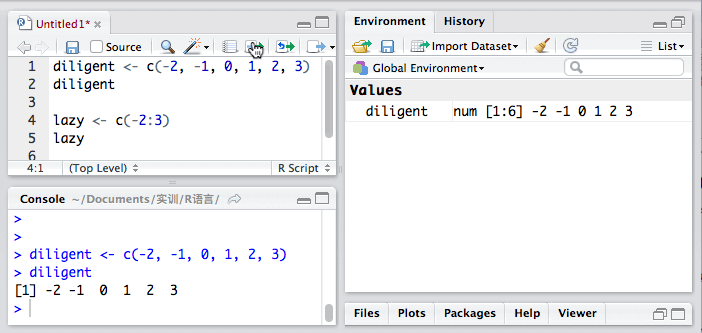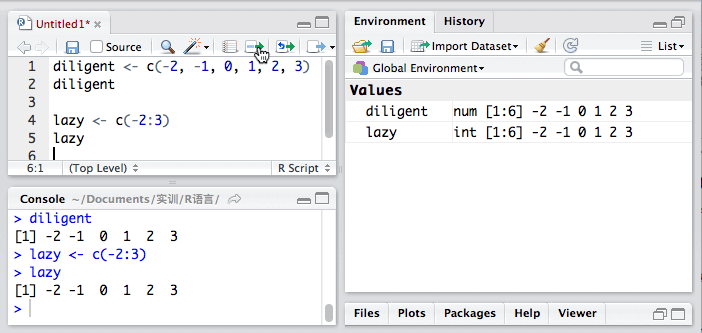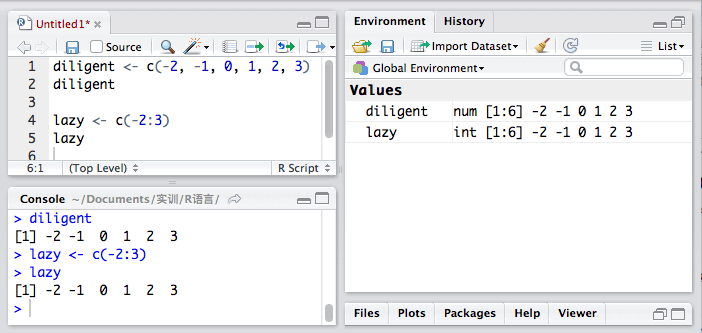
虽然这样很方便,一个冒号就搞定了,但是,:运算符有个致命缺点,那就是一次只能跳一步。
哪有什么办法可以随意设定步长呢?
用函数seq():
seq()有两个参数,分别是by 和 length.out。by参数用来设定步长,而length.out参数是用来设定数据段的“块数”的。
seq(2, 8, by = 1)
seq(3, 15, length.out = 5)
1
2
1
2
1
2
1
2
让我们来看看它怎么用。
注意!对于seq()函数,不能设置这样步数的递减:
seq(10, 9.5, by=0.1)
1
1
1
1
只能这样递减:
seq(10, 9.5, by=-0.1)
1
1
1
1
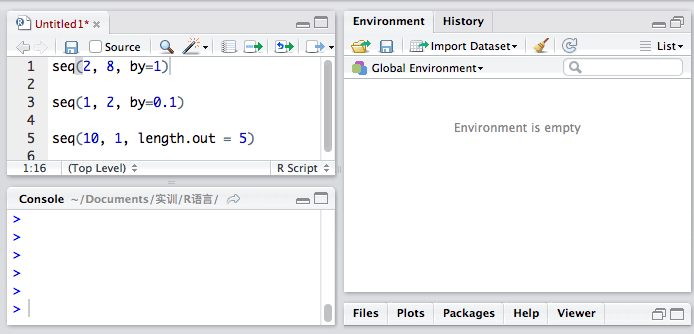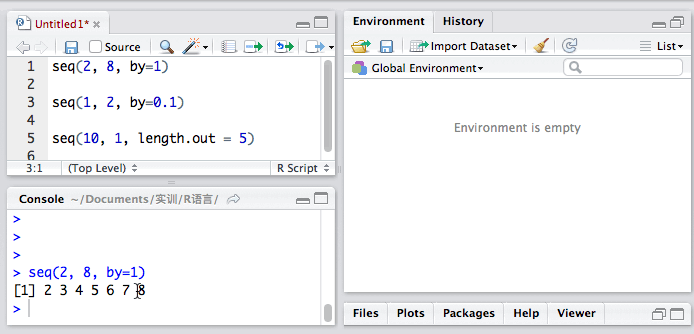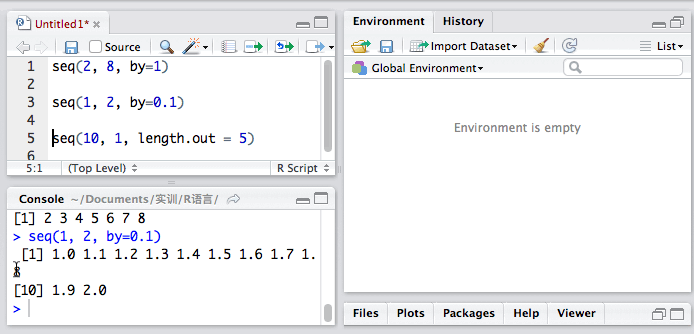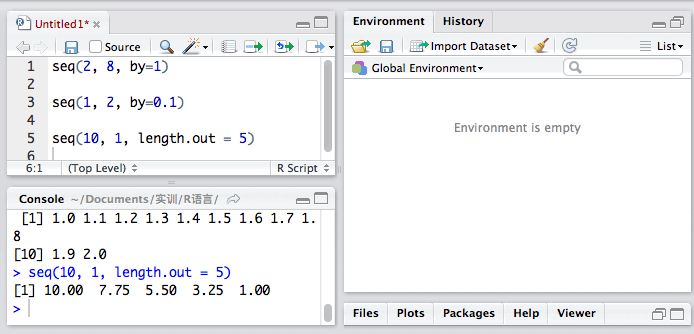
请看下面的seq()函数
seq(10, 1, length.out = 5)
1
1
1
1
它给我们返回了5个数值10.00 7.75 5.50 3.25 1.00,它们的步长是 -2.25。
可以看出来,R可以均匀的帮我们按length.out的值把数值切开。
还有一个让向量操作更方便的函数,叫rep()函数,它就像我们的赋值粘贴功能,让你的向量可以指定次数的复制。
rep(c('男生'), 3)
1
1
1
1
"男生" "男生" "男生"
rep(c(1:3), 4)
1
1
1
1
1 2 3 1 2 3 1 2 3 1 2 3
其实,向量之间也是可以运算的。比如下面这样:
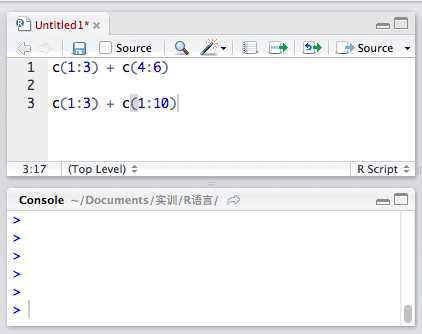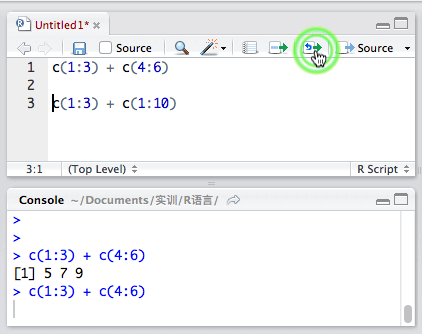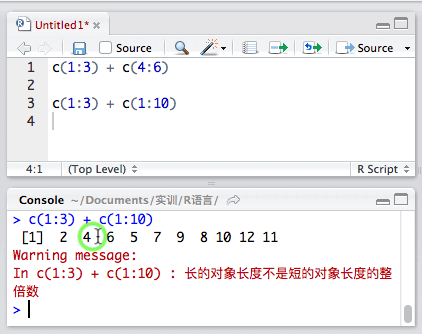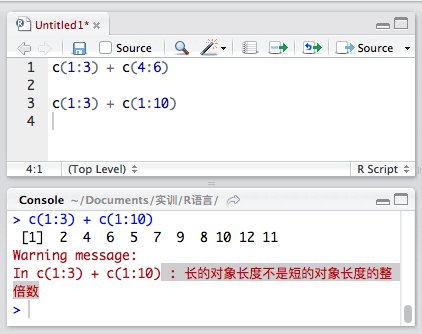
两个向量长度相等时,向量间的运算是相应位置的数字进行运算,运算后结果返回原位置。
但如果长度不相等就会警告我们。
Warning message:长的对象长度不是短的对象长度的整倍数
我们可以无视警告,因为它还是老老实实算出来了。看下图就明白了!
原来,我们的短向量,被硬生生拉长了。
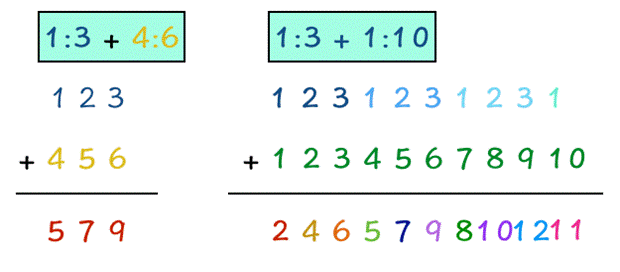
最后,对于向量化计算,还有一个原则就是,避免使用for循环。因为for循环会有明显效率不足的缺点。执行起来比向量化计算的方法慢得多。for循环我们以后会讲到。
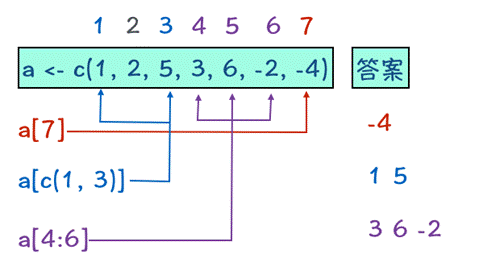
如何访问向量中的数据
通过在[]中给出元素所在位置的数值,我们就可以访问向量中的元素,共有4种访问方式,看下图:

示例如下:
向量中常用的函数
1. 当向量非常长,我们又想知道向量长度的时候,我们可以用length()函数来统计向量长度。比如:
x <- c("a", "b", "c")
length(x)
1
2
1
2
1
2
1
2
将会返回3。
1. 我们还可以对向量中各元素进行命名:
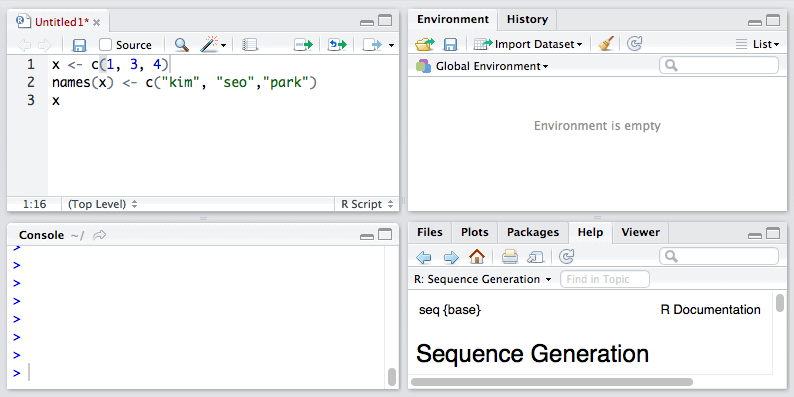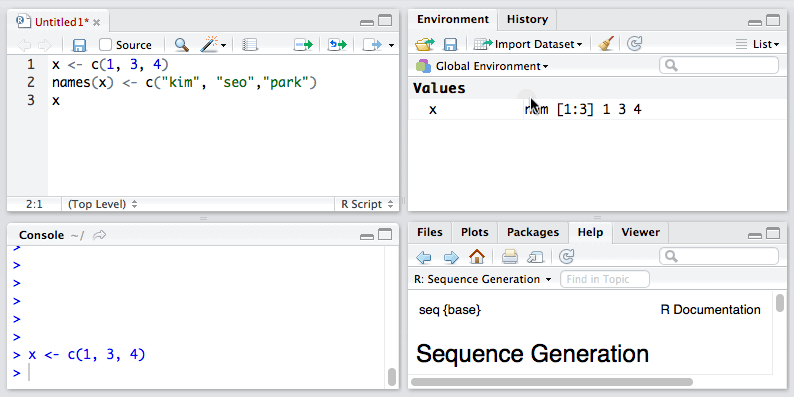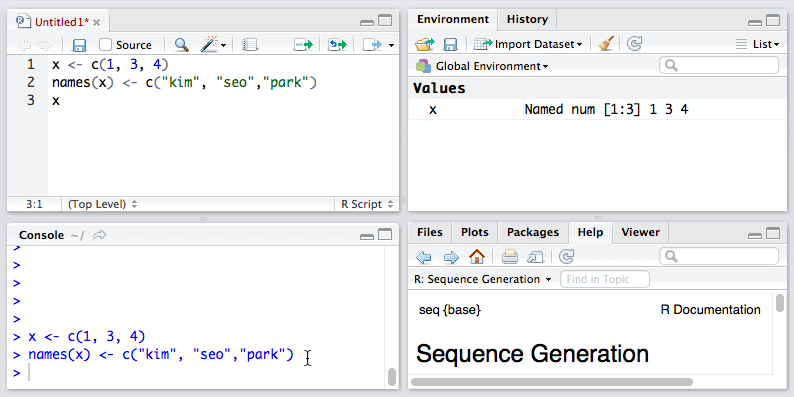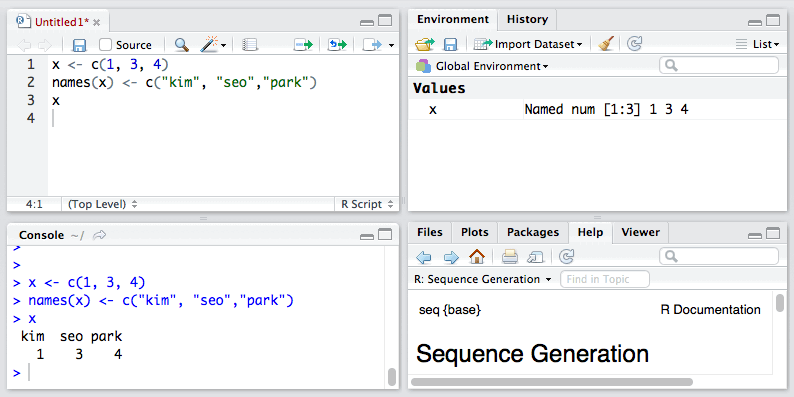
当然我们也可以使用元素的名称访问向量中的元素。
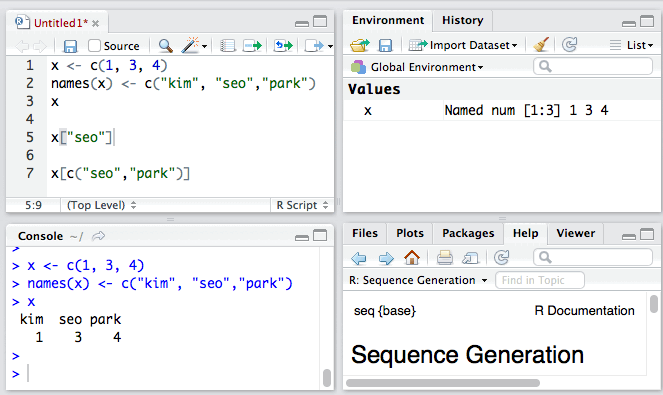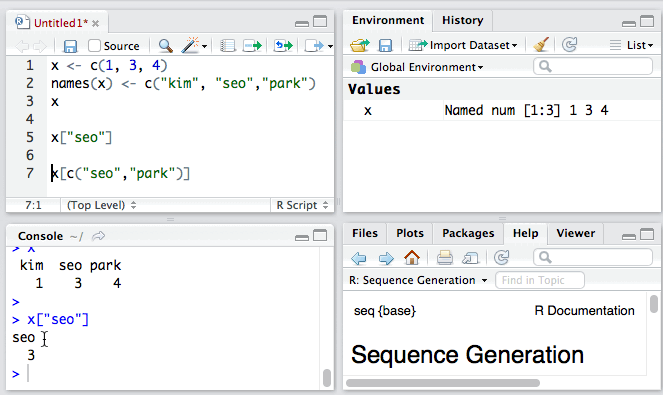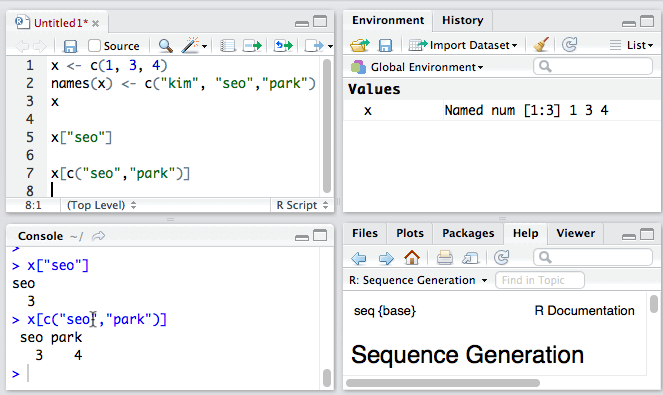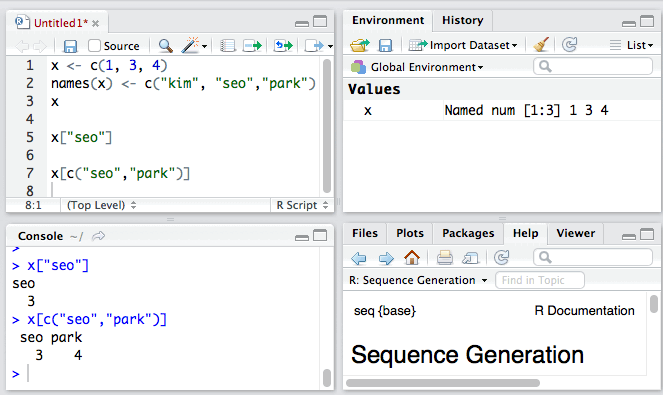
与命名元素类似,我们也可以使用names()函数来查看向量中某个指定元素的名称。例如:
names(x) [2]
1
1
1
1
查看向量第二个元素的名称,输出为"seo"。
编程要求
请仔细阅读右侧代码,根据方法内的提示,在Begin - End区域内进行代码补充。
测试说明
补充完代码后,点击测评,平台会对你编写的代码进行测试,当你的结果与预期输出一致时,即为通过。
