Scrapy爬虫基础
一、实验目的
1、Scrapy框架以及XPath语言的相关知识。
二、实验设备与器件
PC机、phpstudy(wamp环境)、sublime text或者php storm工具
三、实验内容
相关知识
Scrapy是一套基于Twisted的异步处理框架,是纯Python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松地实现一个爬虫,用来抓取网页内容或者各种图片。Scrapy运行于Linux/Windows/MacOS等多种环境,具有速度快、扩展性强、使用简便等特点。即便是新手,也能迅速学会使用Scrapy编写所需要的爬虫程序。Scrapy可以在本地运行,也能部署到云端实现真正的生产级数据采集系统。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy框架概述
Scrapy示意图如下所示。
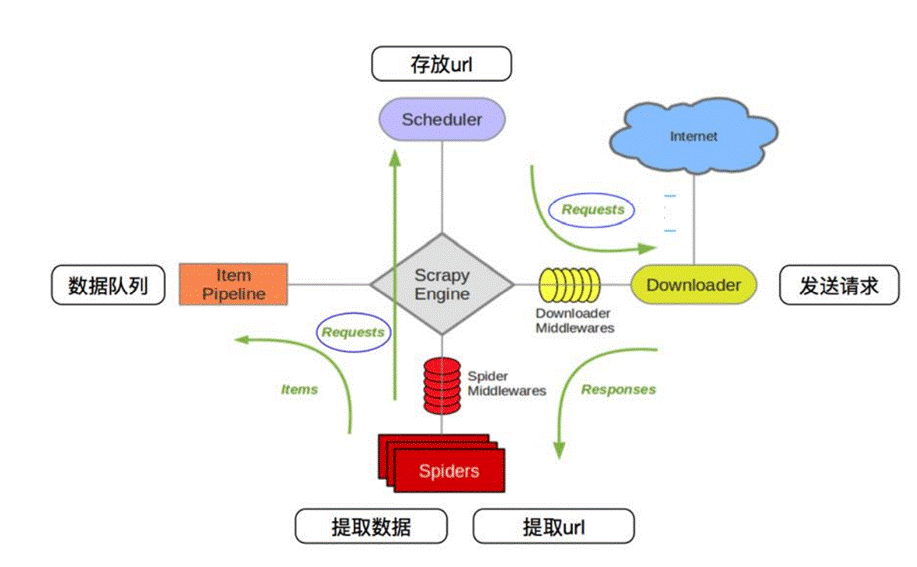
Scrapy包括以下组成部分:
· Scrapy引擎(Engine)。Scrapy引擎相当于一个中枢站,负责调度器、项目管理、下载器和爬虫四个组件之间的通信。例如:将接收到的爬虫发来的URL发送给调度器,将爬虫的存储请求发送项目管道。调度器发送的请求会被Scrapy引擎提交到下载器进行处理,而下载器处理完成后会发送响应给Scrapy引擎,Scrapy引擎将其发送至爬虫进行处理。
· 爬虫(Spiders)爬虫相当于一个解析器,负责接收Scrapy引擎发送过来的响应,对其进行解析,开发人员可以在其内部编写解析规则。解析好后可以发送存储请求给Scrapy引擎。爬虫解析出的新的URL后。可以向Scrapy引享发送。注意,入口URL也存储在爬虫中。
· 下载器(Downloader)。下载器用于下载搜索引擎发送的所有请求,并将网页内容返回给爬虫。下载器建立在Twisted这个高效的异步模型之上。
· 调度器(Scheduler)。调度器可以理解成一个队列,存储Scrapy引擎发送过来的URL,并按顺序取出URL发送给Scrapy引擎进行请求操作。
· 项日管道(Item Pipeline)。项目管道是保存数据用的,它负责处理爬虫获取的项目,并进行处理,包括去重、持久化存储(如存数据库或写入文件)等
· 下载器中间件(Downloader Middlewares)。下载器中间件是位于Scrapy引擎和下载器之间的框架,主要用于处理Scrapy引擎与下载器之间的请求及响应,类似于自定义扩展下载功能的组件。
· 爬虫中间件(Spider Middlewares)。爬虫中间件是介于Scrapy引擎和爬虫之间的框架,主要工作是处理爬虫的响应输入和请求输出。
· 调度器中间件(Scheduler Middlewares)。调度器中间件是介于Scrapy引擎和调度器之间的中间件,用于处理从Scrapy引擎发送到调度器的请求和响应,可以自定义扩展和操作搜索引擎与爬虫中间“通信”的功能组件(如进入爬虫的请求和从爬虫出去的请求)。
Scrapy工作流
Scrapy工作流也叫作“运行流程”或“数据处理流程”,由Scrapy引擎控制。其主要的运行步骤如下:
· Scrapy引擎从调度器中取出一个URL用于接下来的抓取。
· Scrapy引擎把URL封装成一个请求并传给下载器。
· 下载器把资源下载下来,并封装成应答包。
· 爬虫解析应答包。
· 如果解析出的是项目,则交给项目管道进行进一步的处理。
· 如果解析出的是链接(URL),则把URL交给调度器等待抓取。
XPath语言
XPath(XML Path Language)是一门在XML和HTML文档中查找信息的语言,可用来在XML和HTML文档中对元素和属性进行遍历。简单来说,网页数据是以超文本的形式来呈现的,想要获取里面的数据,就要按照一定的规则来进行数据的处理,这种规则就叫做XPath。XPath提供了超过100个内建函数,几乎所有要定位的节点都可以用XPath来定位,在做网络爬虫时可以使用XPath提取所需的信息。
基本术语
XML文档通常可以被看作一棵节点树。在XML中,有元素、属性、文本、命名空间、处理指令、注释以及文档节点等七种类型的节点,其中,元素节点是最常用的节点。下面是一个HTML文档中的代码:
<html>
<head><title>BigData Software</title></head>
<p class="title"><b>BigData Software</b></p>
<p class="bigdata">There are three famous bigdata software;and their names are
<a href="http://example.com/hadoop" class="hadoop" id="link1">Hadoop</a>,
<a href="http://example.com/spark" class="spark" id="link2">Spark</a>and
<a href="http://example.com/flink" class="flink" id="link3"><!--Flink--></a>;
and they are widely used in real application.</p>
<p class="bigdata">...</p></html>
1
2
3
4
5
6
7
8
9
10
上面的HTML文档中,<html>是文档节点,是元素节点,class="title"是属性节点。节点之间存在下面几种关系:
· 父节点:每个元素和属性都有一个父节点。例如,html节点是head节点和p节点的父节点;head节点是title节点的父节点;第二个p节点是中间三个a节点的父节点。
· 子节点:每一个元素节点的下一个直接节点是该元素节点的子节点。每个元素节点可以有零个、一个或多个子节点。例如,title节点是head节点的子节点。
· 兄弟节点:拥有相同父节点的节点,就是兄弟节点。例如,第二个p节点中的三个a节点就是兄弟节点;head节点和中间三个p节点就是兄弟节点;title节点和a节点就不是兄弟节点,因为不是同一个父节点。
· 祖先节点:节点的父节点以及父节点的父节点等,称作“祖先节点”。例如,html节点和head节点是title节点的祖先节点。
· 后代节点:节点的子节点以及子节点的子节点等,称作“后代节点”。例如,html节点的后代节点有head、title、b、p以及a节点。
基本语法
XML/HTML文档是由标签构成的,所有的标签都有很强的层级关系。基于这种层级关系,XPath语法能够准确定位我们所需要的信息。XPath使用路径表达式来选取XML/HTML文档中的节点,这个路径表达式和普通计算机文件系统中见到的路径表达式非常相似。在XPath语法中,我们直接使用路径来选取,再加上适当的谓语或函数进行指定,就可以准确定位到指定的节点。
节点选取
XPath选取节点时,是沿着路径到达目标,下表列出了常用的表达式。
表达式 |
描述 |
nodename |
选取nodename节点的所有子节点 |
/ |
从根节点开始选取 |
// |
从当前文档选取所有匹配的节点,而不考虑它们的位置 |
@ |
选取属性 |
. |
选取当前节点 |
… |
选取当前节点的父节点 |
“/”可以理解为绝对路径,需要从根节点开始;“./”则是相对路径,可以从当前节点开始;“…/”则是先返回上一节点,从上一节点开始。这与普通计算机的文件系统类似。
下面给出测试这些表达式的简单实例,这里需要用到lxml中的etree库,在使用之前需要执行如下命令安装lxml库:
pip install lxm
1
下面是实例代码:
html_text = """
<html>
<body>
<head><title>BigData Software</title></head>
<p class="title"><b>BigData Software</b></p>
<p class="bigdata">There are three famous bigdata software;and their names are
<a href="http://example.com/hadoop" class="bigdata Hadoop"
id="link1">Hadoop</a>,
<a href="http://example.com/spark" class="bigdata Spark" id="link2">Spark</a>and
<a href="http://example.com/flink" class="bigdata Flink" id="link3"><!--Flink--></a>;
and they are widely used in real application.</p>
<p class="bigdata">others</p>
<p>……</p>
</body>
</html>
"""from lxml import etree
html = etree.HTML(html_text)
html_data = html.xpath('body')print(html_data)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
结果如下:
[<Element body at 0x1608dda2d80>]
1
可以看出,html.xpath('body')的输出结果不是像HTML里面那样显示的标签,其实这就是我们所要的元素,只不过我们还需要再进行一步操作,也就是使用etree中的tostring()方法将其进行转换。此外,html.xpath('body')的输出结果是一个列表,因此,我们可以使用for循环来遍历列表,具体代码如下:
for element in html_data:
print(etree.tostring(element))
1
2
由于输出结果比较繁杂,这里没有给出,但是观察结果可以发现,它是标签<body>中的子节点。
“//”表示全局搜索,比如,“//p”可以将所有的
标签搜索出来。“/”表示在某标签下进行搜索,只能搜索子节点,不能搜索子节点的子节点。简单来说,“//”可以进行跳级搜索,“/”只能在本级上进行搜索,不能跳跃。下面是具体实例:
· 逐级搜索
html_data = html.xpath('/html/body/p/a')for element in html_data:
print(etree.tostring(element))
1
2
3
· 跳级搜索
html_data = html.xpath('//a')for element in html_data:
print(etree.tostring(element))
1
2
3
上面两段代码的执行结果相同,具体如下:
b'<a href="http://example.com/hadoop" class="bigdata Hadoop" id="link1">Hadoop</a>,\n '
b'<a href="http://example.com/spark" class="bigdata Spark" id="link2">Spark</a>and\n '
b'<a href="http://example.com/flink" class="bigdata Flink" id="link3"><!--
Flink--></a>;\n and they are widely used in real application.'
1
2
3
4
5
6
可以在方括号内添加“@”,将标签属性填进去,这样就可以准确地将含有该标签属性的部分提取出来,示例代码如下:
html_data = html.xpath('//p/a[@class="bigdata Spark"]')
for element in html_data:
print(etree.tostring(element))
1
2
3
上面代码的执行结果如下:
b'<a href="http://example.com/spark" class="bigdata Spark" id="link2">Spark</a>and\n '
1
2
谓语
直接使用前面介绍的方法可以定位到多数我们需要的节点,但是有时候我们需要查找某个特定的节点或者包含某个指定值的节点,就要用到谓语。谓语是被嵌在方括号中的。下表列出了一些带有谓语的路径表达式及其描述的内容。
路径表达式 |
描述 |
//body/p[k] |
选取所有body下第k个标签(k取值从1开始) |
//body/p[last()] |
选取所有body下最后一个p标签 |
//body/p[last()-1] |
选取所有body下倒数第二个p标签 |
//body/p[position()<3] |
选取所有body下的前两个p标签 |
//body/p[@class] |
选取所有body下带有class属性的p标签 |
//body/p[@class=“bigdata”] |
选取所有body下,class为bigdata的p标签 |
选取所有body下,class为bigdata的p标签,代码如下:
html_data = html.xpath('//body/p[@class="bigdata"]')for element in html_data:
print(etree.tostring(element))
1
2
3
上面代码执行结果如下:
b'<p class="bigdata">There are three famous bigdata software;and their names are\n<a href="http://example.com/hadoop" class="bigdata Hadoop" id="link1">Hadoop</a>,\n<a href="http://example.com/spark" class="bigdata Spark" id="link2">Spark</a>and\n<a href="http://example.com/flink" class="bigdata Flink" id="link3"><!--Flink--></a>;\n
and they are widely used in real application.</p>\n '
b'<p class="bigdata">...</p>\n '
1
2
3
4
5
6
函数
XPath中提供超过100个内建函数用于字符串值、数值、日期和时间比较序列处理等操作,极大地方便了我们定位获取所需要的信息。下表列出了几个常用的函数。
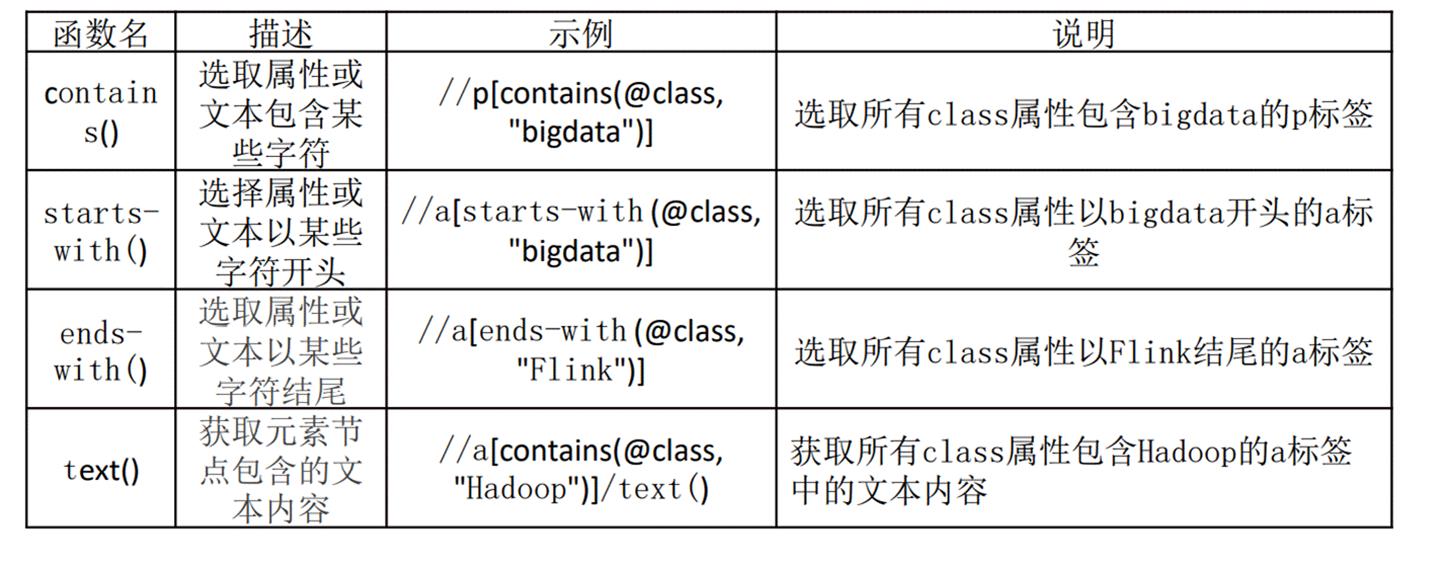
下面是示例代码,获取所有class属性包含bigdata的a标签中的文本内容,代码如下:
html = etree.HTML(html_text
html_data = html.xpath('//a[contains(@class, "bigdata")]/text()')print(html_data)
1
2
3
结果如下:
['Hadoop', 'Spark']
1
在演示的HTML代码中,还有一个a标签也符合代码的要求,但是因为其文本内容是注释,所以不会被抽取出来显示。
编程要求
请在右侧Begin-End区域中补全代码完成以下任务:
· 输出 body 节点的子节点;
· 逐级搜索a标签;
· 跳级搜索a标签;
· 提取带有class为color red的部分;
· 提取所有body下class为Color的p标签;
· 提取所有class属性包含color的a标签中的文本内容。
测试说明
在按编程要求完成操作后,请点击评测按钮,系统会自动对你的操作进行评测。
当你的结果与预期输出一致时,即为通过。
