分类分析综合实验
一、实验目的
1、熟悉典型的分类算法应用
2、熟悉分类算法的评估与模型选择
二、实验设备与器件
计算机、Python语言开发环境
三、实验内容
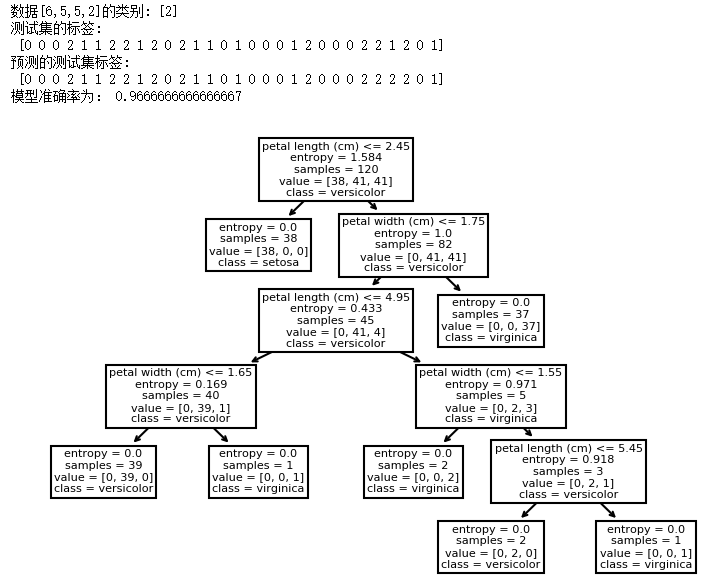
1.利用决策树算法对Iris数据集构建决策树。
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn import tree
from sklearn.model_selection import train_test_split
iris = load_iris()
X_train,X_test,y_train,y_test=train_test_split(iris.data, iris.target,test_size=0.20,random_state=30,shuffle=True)
clf = tree.DecisionTreeClassifier(criterion='entropy')
# criterion缺省为'gini'
clf = clf.fit(X_train,y_train)
plt.figure(dpi=150)
tree.plot_tree(clf, feature_names=iris.feature_names, class_names=iris.target_names)
# feature_names=iris.feature_names设置决策树中显示的特征名称
# 预测数据[6,5,5,2]的类别
print('数据[6,5,5,2]的类别:',clf.predict([[6,5,5,2]]))
print('测试集的标签:\n',y_test)
y_pre=clf.predict(X_test)
print('预测的测试集标签:\n',y_pre)
print('模型准确率为:',clf.score(X_test,y_test))
2.对Iris数据集进行朴素贝叶斯分类。
from sklearn.datasets import load_iris
from sklearn.naive_bayes import GaussianNB
iris = load_iris()
clf = GaussianNB()#设置高斯贝叶斯分类器
clf.fit(iris.data,iris.target)#训练分类器
y_pred = clf.predict(iris.data)#预测
print("Number of mislabeled points out of %d points:%d" %(iris.data.shape[0],(iris.target!= y_pred).sum()))
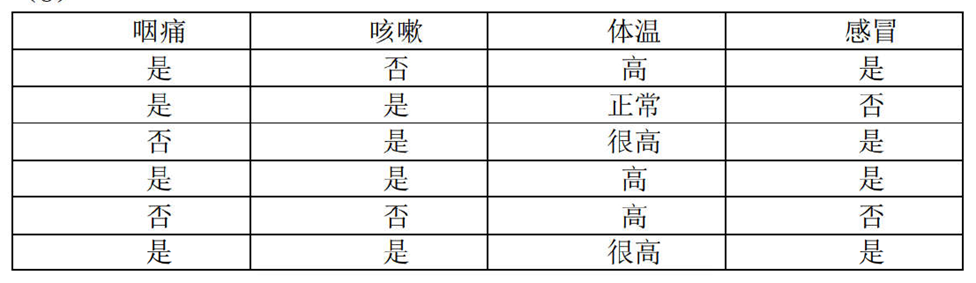
3.使用如下表所示的数据,利用决策树算法预测是否感冒。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 创建数据框
data = {
'头痛': [0, 1, 1, 0, 1],
'咳嗽': [1, 1, 0, 1, 0],
'喉咙痛': [1, 0, 1, 1, 1],
'发烧': [0, 1, 1, 0, 1],
'是否感冒': [0, 1, 1, 0, 1]
}
df = pd.DataFrame(data)
# 分离特征和目标变量
X = df.drop('是否感冒', axis=1)
y = df['是否感冒']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建决策树分类器
clf = DecisionTreeClassifier()
# 训练模型
clf.fit(X_train, y_train)
# 预测
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
